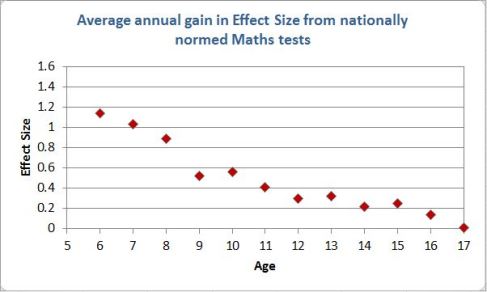
In an earlier post we discovered that John Hattie had admitted (quietly) that half of the Statistics in Visible Learning were incorrect. John Hattie uses two statistics in the book, the ‘Effect Size’ and the ‘CLE’. All of the CLEs are wrong through-out the book.
Now, I didn’t really know why they were wrong, I thought, maybe he was using a computer program to calculate them and it had been set up incorrectly. I didn’t know. Until I received this comment from Per-Daniel Liljegren. He was giving a seminar on Visible Learning for some teachers in Sweden and didn’t understand some of what he’d found, so, he wrote to Debra Masters, Director of Visible Learning Plus, asking for help.
“Now, when preparing the very first seminar, I was very puzzled over the CLEs in Hattie’s Visible Learning. It seems to me that most of the CLEs are simply the Effect Size, d, divided by the square root of 2.
Should not the CLE be some integral from -infinity to d divided by the square root of 2?”
And if you grab your copy of Visible Learning and check, he’s right! The CLEs are just the Effect Size divided by the square root of 2.
He never received a reply to his letter.
If we look at this article that tells us how to calculate the CLE – How to calculate the Common Language Effect Size Statistic – we see that dividing by the square root of 2 actually finds the z value. This should then have been converted into the probability using standard Normal distribution tables, a very basic statistical technique that we teach to Year 12s in S1 A Level.
Throughout the book, Visible Learning, John Hattie has calculated the z values and used them as his CLEs when he should have converted them into probabilities.
Three very worrying things about all this –
1. John Hattie doesn’t know the difference between z values and the probabilities you get from z values. Really, really, basic stuff.
2. John Hattie knows about this mistake but has chosen not to publicise it. This could mean that many teachers are still relying on it to instruct their teaching.
2. No-one picked up on it for years, despite the fact the CLE is meant to be a probability. So, throughout the book he is saying that probability can be negative or more than 100%. So, who is checking John Hattie’s work? Because the academic educational establishment doesn’t appear to be.
Again we are left with two options to choose from
1. John Hattie is a genius who is doing things that even Mathematicians don’t understand.
2. John Hattie is a well meaning man with a Social Sciences degree who has made a mistake in using statistical techniques he didn’t realise were unknown to Mathematicians and incorrect.
The choice is yours.